#Fine-tuning LLM for RAG
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
China blocked Tumblr because of pornography and censorship problems in 2013.
Text
Think Smarter, Not Harder: Meet RAG

How do RAG make machines think like you?
Imagine a world where your AI assistant doesn't only talk like a human but understands your needs, explores the latest data, and gives you answers you can trust—every single time. Sounds like science fiction? It's not.
We're at the tipping point of an AI revolution, where large language models (LLMs) like OpenAI's GPT are rewriting the rules of engagement in everything from customer service to creative writing. here's the catch: all that eloquence means nothing if it can't deliver the goods—if the answers aren't just smooth, spot-on, accurate, and deeply relevant to your reality.
The question is: Are today's AI models genuinely equipped to keep up with the complexities of real-world applications, where context, precision, and truth aren't just desirable but essential? The answer lies in pushing the boundaries further—with Retrieval-Augmented Generation (RAG).
While LLMs generate human-sounding copies, they often fail to deliver reliable answers based on real facts. How do we ensure that an AI-powered assistant doesn't confidently deliver outdated or incorrect information? How do we strike a balance between fluency and factuality? The answer is in a brand new powerful approach: Retrieval-Augmented Generation (RAG).
What is Retrieval-Augmented Generation (RAG)?
RAG is a game-changing technique to increase the basic abilities of traditional language models by integrating them with information retrieval mechanisms. RAG does not only rely on pre-acquired knowledge but actively seek external information to create up-to-date and accurate answers, rich in context. Imagine for a second what could happen if you had a customer support chatbot able to engage in a conversation and draw its answers from the latest research, news, or your internal documents to provide accurate, context-specific answers.
RAG has the immense potential to guarantee informed, responsive and versatile AI. But why is this necessary? Traditional LLMs are trained on vast datasets but are static by nature. They cannot access real-time information or specialized knowledge, which can lead to "hallucinations"—confidently incorrect responses. RAG addresses this by equipping LLMs to query external knowledge bases, grounding their outputs in factual data.
How Does Retrieval-Augmented Generation (RAG) Work?
RAG brings a dynamic new layer to traditional AI workflows. Let's break down its components:
Embedding Model
Think of this as the system's "translator." It converts text documents into vector formats, making it easier to manage and compare large volumes of data.
Retriever
It's the AI's internal search engine. It scans the vectorized data to locate the most relevant documents that align with the user's query.
Reranker (Opt.)
It assesses the submitted documents and score their relevance to guarantee that the most pertinent data will pass along.
Language Model
The language model combines the original query with the top documents the retriever provides, crafting a precise and contextually aware response. Embedding these components enables RAG to enhance the factual accuracy of outputs and allows for continuous updates from external data sources, eliminating the need for costly model retraining.
How does RAG achieve this integration?
It begins with a query. When a user asks a question, the retriever sifts through a curated knowledge base using vector embeddings to find relevant documents. These documents are then fed into the language model, which generates an answer informed by the latest and most accurate information. This approach dramatically reduces the risk of hallucinations and ensures that the AI remains current and context-aware.
RAG for Content Creation: A Game Changer or just a IT thing?
Content creation is one of the most exciting areas where RAG is making waves. Imagine an AI writer who crafts engaging articles and pulls in the latest data, trends, and insights from credible sources, ensuring that every piece of content is compelling and accurate isn't a futuristic dream or the product of your imagination. RAG makes it happen.
Why is this so revolutionary?
Engaging and factually sound content is rare, especially in today's digital landscape, where misinformation can spread like wildfire. RAG offers a solution by combining the creative fluency of LLMs with the grounding precision of information retrieval. Consider a marketing team launching a campaign based on emerging trends. Instead of manually scouring the web for the latest statistics or customer insights, an RAG-enabled tool could instantly pull in relevant data, allowing the team to craft content that resonates with current market conditions.
The same goes for various industries from finance to healthcare, and law, where accuracy is fundamental. RAG-powered content creation tools promise that every output aligns with the most recent regulations, the latest research and market trends, contributing to boosting the organization's credibility and impact.
Applying RAG in day-to-day business
How can we effectively tap into the power of RAG? Here's a step-by-step guide:
Identify High-Impact Use Cases
Start by pinpointing areas where accurate, context-aware information is critical. Think customer service, marketing, content creation, and compliance—wherever real-time knowledge can provide a competitive edge.
Curate a robust knowledge base
RAG relies on the quality of the data it collects and finds. Build or connect to a comprehensive knowledge repository with up-to-date, reliable information—internal documents, proprietary data, or trusted external sources.
Select the right tools and technologies
Leverage platforms that support RAG architecture or integrate retrieval mechanisms with existing LLMs. Many AI vendors now offer solutions combining these capabilities, so choose one that fits your needs.
Train your team
Successful implementation requires understanding how RAG works and its potential impact. Ensure your team is well-trained in deploying RAG&aapos;s technical and strategic aspects.
Monitor and optimize
Like any technology, RAG benefits from continuous monitoring and optimization. Track key performance indicators (KPIs) like accuracy, response time, and user satisfaction to refine and enhance its application.
Applying these steps will help organizations like yours unlock RAG's full potential, transform their operations, and enhance their competitive edge.
The Business Value of RAG
Why should businesses consider integrating RAG into their operations? The value proposition is clear:
Trust and accuracy
RAG significantly enhances the accuracy of responses, which is crucial for maintaining customer trust, especially in sectors like finance, healthcare, and law.
Efficiency
Ultimately, RAG reduces the workload on human employees, freeing them to focus on higher-value tasks.
Knowledge management
RAG ensures that information is always up-to-date and relevant, helping businesses maintain a high standard of knowledge dissemination and reducing the risk of costly errors.
Scalability and change
As an organization grows and evolves, so does the complexity of information management. RAG offers a scalable solution that can adapt to increasing data volumes and diverse information needs.
RAG vs. Fine-Tuning: What's the Difference?
Both RAG and fine-tuning are powerful techniques for optimizing LLM performance, but they serve different purposes:
Fine-Tuning
This approach involves additional training on specific datasets to make a model more adept at particular tasks. While effective for niche applications, it can limit the model's flexibility and adaptability.
RAG
In contrast, RAG dynamically retrieves information from external sources, allowing for continuous updates without extensive retraining, which makes it ideal for applications where real-time data and accuracy are critical.
The choice between RAG and fine-tuning entirely depends on your unique needs. For example, RAG is the way to go if your priority is real-time accuracy and contextual relevance.
Concluding Thoughts
As AI evolves, the demand for RAG AI Service Providers systems that are not only intelligent but also accurate, reliable, and adaptable will only grow. Retrieval-Augmented generation stands at the forefront of this evolution, promising to make AI more useful and trustworthy across various applications.
Whether it's a content creation revolution, enhancing customer support, or driving smarter business decisions, RAG represents a fundamental shift in how we interact with AI. It bridges the gap between what AI knows and needs to know, making it the tool of reference to grow a real competitive edge.
Let's explore the infinite possibilities of RAG together
We would love to know; how do you intend to optimize the power of RAG in your business? There are plenty of opportunities that we can bring together to life. Contact our team of AI experts for a chat about RAG and let's see if we can build game-changing models together.
#RAG#Fine-tuning LLM for RAG#RAG System Development Companies#RAG LLM Service Providers#RAG Model Implementation#RAG-Enabled AI Platforms#RAG AI Service Providers#Custom RAG Model Development
0 notes
Text
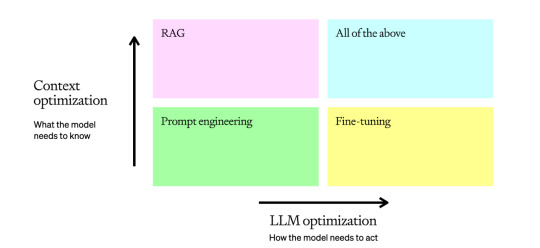
LLM optimization context
0 notes
Text
RAG vs Fine-Tuning: Choosing the Right Approach for Building LLM-Powered Chatbots

Imagine having an ultra-intelligent assistant ready to answer any question. Now, imagine making it even more capable, specifically for tasks you rely on most. That’s the power—and the debate—behind Retrieval-Augmented Generation (RAG) and Fine-Tuning. These methods act as “training wheels,” each enhancing your AI’s capabilities in unique ways.
RAG brings in current, real-world data whenever the model needs it, perfect for tasks requiring constant updates. Fine-Tuning, on the other hand, ingrains task-specific knowledge directly into the model, tailoring it to your exact needs. Selecting between them can dramatically influence your AI’s performance and relevance.
Whether you’re building a customer-facing chatbot, automating tailored content, or optimizing an industry-specific application, choosing the right approach can make all the difference.
This guide will delve into the core contrasts, benefits, and ideal use cases for RAG and Fine-Tuning, helping you pinpoint the best fit for your AI ambitions.
Key Takeaways:
Retrieval-Augmented Generation (RAG) and Fine-Tuning are two powerful techniques for enhancing Large Language Models (LLMs) with distinct advantages.
RAG is ideal for applications requiring real-time information updates, leveraging external knowledge bases to deliver relevant, up-to-date responses.
Fine-Tuning excels in accuracy for specific tasks, embedding task-specific knowledge directly into the model’s parameters for reliable, consistent performance.
Hybrid approaches blend the strengths of both RAG and Fine-Tuning, achieving a balance of real-time adaptability and domain-specific accuracy.
What is RAG?
Retrieval-Augmented Generation (RAG) is an advanced technique in natural language processing (NLP) that combines retrieval-based and generative models to provide highly relevant, contextually accurate responses to user queries. Developed by OpenAI and other leading AI researchers, RAG enables systems to pull information from extensive databases, knowledge bases, or documents and use it as part of a generated response, enhancing accuracy and relevance.
How RAG Works?

Retrieval Step
When a query is received, the system searches through a pre-indexed database or corpus to find relevant documents or passages. This retrieval process typically uses dense embeddings, which are vector representations of text that help identify the most semantically relevant information.
Generation Step
The retrieved documents are then passed to a generative model, like GPT or a similar transformer-based architecture. This model combines the query with the retrieved information to produce a coherent, relevant response. The generative model doesn’t just repeat the content but rephrases and contextualizes it for clarity and depth.
Combining Outputs
The generative model synthesizes the response, ensuring that the answer is not only relevant but also presented in a user-friendly way. The combined information often makes RAG responses more informative and accurate than those generated by standalone generative models.
Advantages of RAG

Improved Relevance
By incorporating external, up-to-date sources, RAG generates more contextually accurate responses than traditional generative models alone.
Reduced Hallucination
One of the significant issues with purely generative models is “hallucination,” where they produce incorrect or fabricated information. RAG mitigates this by grounding responses in real, retrieved content.
Scalability
RAG can integrate with extensive knowledge bases and adapt to vast amounts of information, making it ideal for enterprise and research applications.
Enhanced Context Understanding
By pulling from a wide variety of sources, RAG provides a richer, more nuanced understanding of complex queries.
Real-World Knowledge Integration
For companies needing up-to-date or specialized information (e.g., medical databases, and legal documents), RAG can incorporate real-time data, ensuring the response is as accurate and current as possible.
Disadvantages of RAG

Computational Intensity
RAG requires both retrieval and generation steps, demanding higher processing power and memory, making it more expensive than traditional NLP models.
Reliance on Database Quality
The accuracy of RAG responses is highly dependent on the quality and relevance of the indexed knowledge base. If the corpus lacks depth or relevance, the output can suffer.
Latency Issues
The retrieval and generation process can introduce latency, potentially slowing response times, especially if the retrieval corpus is vast.
Complexity in Implementation
Setting up RAG requires both an effective retrieval system and a sophisticated generative model, increasing the technical complexity and maintenance needs.
Bias in Retrieved Data
Since RAG relies on existing data, it can inadvertently amplify biases or errors present in the retrieved sources, affecting the quality of the generated response.
What is Fine-Tuning?

Fine-tuning is a process in machine learning where a pre-trained model (one that has been initially trained on a large dataset) is further trained on a more specific, smaller dataset. This step customizes the model to perform better on a particular task or within a specialized domain. Fine-tuning adjusts the weights of the model so that it can adapt to nuances in the new data, making it highly relevant for specific applications, such as medical diagnostics, legal document analysis, or customer support.
How Fine-Tuning Works?

Pre-Trained Model Selection
A model pre-trained on a large, general dataset (like GPT trained on a vast dataset of internet text) serves as the foundation. This model already understands a wide range of language patterns, structures, and general knowledge.
Dataset Preparation
A specific dataset, tailored to the desired task or domain, is prepared for fine-tuning. This dataset should ideally contain relevant and high-quality examples of what the model will encounter in production.
Training Process
During fine-tuning, the model is retrained on the new dataset with a lower learning rate to avoid overfitting. This step adjusts the pre-trained model’s weights so that it can capture the specific patterns, terminology, or context in the new data without losing its general language understanding.
Evaluation and Optimization
The fine-tuned model is tested against a validation dataset to ensure it performs well. If necessary, hyperparameters are adjusted to further optimize performance.
Deployment
Once fine-tuning yields satisfactory results, the model is ready for deployment to handle specific tasks with improved accuracy and relevancy.
Advantages of Fine-Tuning

Enhanced Accuracy
Fine-tuning significantly improves the model’s performance on domain-specific tasks since it adapts to the unique vocabulary and context of the target domain.
Cost-Effectiveness
It’s more cost-effective than training a new model from scratch. Leveraging a pre-trained model saves computational resources and reduces time to deployment.
Task-Specific Customization
Fine-tuning enables customization for niche applications, like customer service responses, medical diagnostics, or legal document summaries, where specialized vocabulary and context are required.
Reduced Data Requirements
Fine-tuning typically requires a smaller dataset than training a model from scratch, as the model has already learned fundamental language patterns from the pre-training phase.
Scalability Across Domains
The same pre-trained model can be fine-tuned for multiple specialized tasks, making it highly adaptable across different applications and industries.
Disadvantages of Fine-Tuning

Risk of Overfitting
If the fine-tuning dataset is too small or lacks diversity, the model may overfit, meaning it performs well on the fine-tuning data but poorly on new inputs.
Loss of General Knowledge
Excessive fine-tuning on a narrow dataset can lead to a loss of general language understanding, making the model less effective outside the fine-tuned domain.
Data Sensitivity
Fine-tuning may amplify biases or errors present in the new dataset, especially if it’s not balanced or representative.
Computation Costs
While fine-tuning is cheaper than training from scratch, it still requires computational resources, which can be costly for complex models or large datasets.
Maintenance and Updates
Fine-tuned models may require periodic retraining or updating as new domain-specific data becomes available, adding to maintenance costs.
Key Difference Between RAG and Fine-Tuning

Key Trade-Offs to Consider

Data Dependency
RAG’s dynamic data retrieval means it’s less dependent on static data, allowing accurate responses without retraining.
Cost and Time
Fine-tuning is computationally demanding and time-consuming, yet yields highly specialized models for specific use cases.
Dynamic Vs Static Knowledge
RAG benefits from dynamic, up-to-date retrieval, while fine-tuning relies on stored static knowledge, which may age.
When to Choose Between RAG and Fine-Tuning?
RAG shines in applications needing vast and frequently updated knowledge, like tech support, research tools, or real-time summarization. It minimizes retraining requirements but demands a high-quality retrieval setup to avoid inaccuracies. Example: A chatbot using RAG for product recommendations can fetch real-time data from a constantly updated database.
Fine-tuning excels in tasks needing domain-specific knowledge, such as medical diagnostics, content generation, or document reviews. While demanding quality data and computational resources, it delivers consistent results post-training, making it well-suited for static applications. Example: A fine-tuned AI model for document summarization in finance provides precise outputs tailored to industry-specific language.
the right choice is totally depended on the use case of your LLM chatbot. Take the necessary advantages and disadvantages in the list and choose the right fit for your custom LLM development.
Hybrid Approaches: Leveraging RAG and Fine-Tuning Together
Rather than favoring either RAG or fine-tuning, hybrid approaches combine the strengths of both methods. This approach fine-tunes the model for domain-specific tasks, ensuring consistent and precise performance. At the same time, it incorporates RAG’s dynamic retrieval for real-time data, providing flexibility in volatile environments.
Optimized for Precision and Real-Time Responsiveness

With hybridization, the model achieves high accuracy for specialized tasks while adapting flexibly to real-time information. This balance is crucial in environments that require both up-to-date insights and historical knowledge, such as customer service, finance, and healthcare.
Fine-Tuning for Domain Consistency: By fine-tuning, hybrid models develop strong, domain-specific understanding, offering reliable and consistent responses within specialized contexts.
RAG for Real-Time Adaptability: Integrating RAG enables the model to access external information dynamically, keeping responses aligned with the latest data.
Ideal for Data-Intensive Industries: Hybrid models are indispensable in fields like finance, healthcare, and customer service, where both past insights and current trends matter. They adapt to new information while retaining industry-specific precision.
Versatile, Cost-Effective Performance
Hybrid approaches maximize flexibility without extensive retraining, reducing costs in data management and computational resources. This approach allows organizations to leverage existing fine-tuned knowledge while scaling up with dynamic retrieval, making it a robust, future-proof solution.
Conclusion
Choosing between RAG and Fine-Tuning depends on your application’s requirements. RAG delivers flexibility and adaptability, ideal for dynamic, multi-domain needs. It provides real-time data access, making it invaluable for applications with constantly changing information.
Fine-Tuning, however, focuses on domain-specific tasks, achieving greater precision and efficiency. It’s perfect for tasks where accuracy is non-negotiable, embedding knowledge directly within the model.
Hybrid approaches blend these benefits, offering the best of both. However, these solutions demand thoughtful integration for optimal performance, balancing flexibility with precision.
At TechAhead, we excel in delivering custom AI app development around specific business objectives. Whether implementing RAG, Fine-Tuning, or a hybrid approach, our expert team ensures AI solutions drive impactful performance gains for your business.
Source URL: https://www.techaheadcorp.com/blog/rag-vs-fine-tuning-difference-for-chatbots/
0 notes
Text
Comparing Retrieval-Augmented Generation (RAG) and Fine-tuning: Advantages and Limitations
(Images made by author with Microsoft Copilot) In the rapidly evolving landscape of artificial intelligence, two approaches stand out for enhancing the capabilities of language models: Retrieval-Augmented Generation (RAG) and fine-tuning. Each approach offers unique advantages and challenges, making it essential to understand their differences and determine the most suitable approach for…

View On WordPress
0 notes
Text
continuing the theme of 'what can we make LLMs do' (I promise this is all leading to a really in-depth elaboration on some stuff about human thinking derived from that acid trip I keep mentioning, but I need to write some shader code first for a proper visual representation)
here is an interesting series of articles by @cherrvak on attempts to train an LLM to speak in-character as their friend Zef, by using a technique called RAG to pull up relevant samples from the training corpus in order to provide them in the prompt: part one, part two, part three. the technique worked poorly (in terms of style) with newer LLMs that are trained to interact chatbot style, but worked better with a non-finetuned language model.
I think it's interesting because it tries to solve the problem of gettting LLMs out of the helpful 'chatGPT voice' while still maintaining the coherence and context-sensitivity that makes them so surprisingly effective roleplay partners. if I ever end up trying to make an LLM-powered NPC in a game, seems like it will be very useful research.
so far the techniques for shaping LLM output I know about are, in roughly increasing order of computational intensity:
describing what you want in the prompt; depending on the model this might be phrased as instructions, or examples that you want to be extended
control vectors, where you provide pairs of contrasting prompts and then derive from them a set of values to apply as a kind of forcing while the LLM is generating tokens, to push its output in a particular direction
fine-tuning, where you adjust all the weights of the model in the same way as during its original training (gradient descent etc.)
reinforcement learning, such as the RLHF technique used to turn a generic language model into a chatbot like ChatGPT which follows instructions into a chatbot with certain desired behaviours
RAG largely operates on the first of these: the query is fed into a special type of lookup which finds data related to that subject, and is then appended to the prompt. it's remarkably like human memory in a way: situationally, stuff will 'come to mind' since it seems similar to something else, and we can then factor it into things that we will say.
the biggest problem seems to be not to get the LLMs to say something true if it's retrieved from the database/provided to them in the prompt, but to stop them saying something false/irrelevant when they don't have an answer to hand ('hallucination' or 'bullshitting'). as a human, we have the experience of "trying to remember" information - "it's on the tip of my tongue". I wonder if a model could be somehow taught to recognise when it doesn't have the relevant information and poll the database again with a slightly different vector? that said I still am only at the very beginning of learning to drive these things, so I should probably focus on getting the hang of the basics first, like trying out the other three techniques on the list instead of just testing out different prompts.
8 notes
·
View notes
Text
140+ awesome LLM tools that will supercharge your creative workflow
2025: A curated collection of tools to create AI agents, RAG, fine-tune and deploy!
3 notes
·
View notes
Text




Order Now 60% Off
Nespresso Original Line Coffee Pod with 1 Storage Drawer Holder, 50 Capsule Capacity, Black
Available at a lower price from other sellers that may not offer free Prime shipping. Color Black Material Plastic Brand Amazon Basics Product Dimensions 14.9"D x 9.1"W x 2"H Number of Drawers 1
#amazon fba,#amazon,amazon sale,#how to sell on amazon,#amazon fba for beginners,#amazon next sale 2024,#amazon fba tutorial,selling on amazon,#amazon fba step by step,#sell on amazon,how to sell on amazon fba,#upcoming sale on flipkart and amazon,#amazon sale 2023,amazon new sale,#amazon returns,how to sell on amazon for beginners,#alibaba to amazon,next sale on amazon,#how to start selling on amazon,#amazon summer sale 2023,#amazon great indian sale #private ai,#chatgpt offline,#vmware,#nvidia,#fine-tuning ai,#artificial intelligence,#privacy in technology,#zombie apocalypse survival,#vmware private ai foundation,nvidia ai enterprise,wsl installation,llms,deep learning vms,custom ai solutions,#gpus in ai,#rag technology,#private gpt setup,#intel partnership,#ibm watson,#vmware cloud foundation,#networkchuck tutorials,#future of tech,#ai without internet,#data privacy,#because science,#engineering #best product from every brand at sephora,#best hair product,#best product management books,#best product development books,#product research,#best products,best product books,#best trim product,#amazon best products,#best products for eyes,#best product landing page,#best product landing pages,#best matte hair product,#best at sephora,#best way to sell a product,#hair product,#best products for eye bags,#best product development tips,#best products for puffy eyes
#viralpost#viral news#viral products#trendingnow#trendingtopics#trending#viral#amazon#amazing body#affiliate#sales#business#networking#strategy#online shopping#online shop uk#online shops offer#online store#online business#shopping state
3 notes
·
View notes
Text
AI’s Potential: Comparing Dynamic Retrieval and Model Customization in Language Models
Artificial Intelligence has come a long way in understanding and generating human language, thanks largely to advancements in large language models. Among the leading techniques that elevate these models’ capabilities are Retrieval-Augmented Generation and Fine-Tuning. Although both aim to improve AI responses, they do so through very different approaches, each with its own strengths, challenges, and ideal use cases.
The Basics: Tailoring Intelligence vs. Fetching Fresh Knowledge
At its core, Fine-Tuning is about customization. Starting with a broadly trained LLM, fine-tuning adjusts the model’s internal parameters using a specialized dataset. This helps the AI learn domain-specific terminology, nuances, and context, enabling it to understand and respond accurately within a particular field. For example, a fine-tuned model in healthcare would grasp medical abbreviations, treatment protocols, and patient communication subtleties far better than a general-purpose model.
In contrast, Retrieval-Augmented Generation enhances an AI’s answers by combining a pre-trained language model with a dynamic retrieval system. Instead of relying solely on what the model “knows” from training, RAG actively searches external knowledge bases or documents in real-time, pulling in up-to-date or proprietary information. This enables the AI to generate answers grounded in the latest data- even if that data wasn’t part of the original training corpus.
How Fine-Tuning Shapes AI Understanding
Fine-tuning involves carefully retraining the model on a curated dataset, often domain-specific. The process tweaks the model’s neural network weights to improve accuracy and reduce errors like hallucinations or irrelevant responses. Importantly, it uses a lower learning rate than the initial training to preserve the model’s general language capabilities while specializing it.
This method excels when the task demands deep familiarity with specialized language. For instance, healthcare fine-tuning enables the model to correctly interpret abbreviations like “MI” as “Myocardial Infarction” and provide contextually precise answers about diagnosis or treatment. However, fine-tuning can be resource-intensive and might not adapt quickly to new information after training.
Why RAG Brings Real-Time Intelligence
RAG models address a key limitation of static LLMs: outdated or missing knowledge. Since it retrieves relevant documents on demand, RAG allows AI to incorporate fresh, specific data into its responses. This is invaluable in fast-evolving domains or cases requiring access to confidential enterprise data not included during model training.
Imagine querying about the interactions of a novel drug in a healthcare assistant. A fine-tuned model may understand the medical terms well, but might lack details on the latest drug interactions. RAG can fetch current research, patient records, or updated guidelines instantly, enriching the answer with real-world, dynamic information.
The Power of Combining Both Approaches
The real magic happens when fine-tuning and RAG are combined. Fine-tuning equips the model with a strong grasp of domain language and concepts, while RAG supplements it with the freshest and most relevant data.
Returning to the healthcare example, the fine-tuned model decodes complex medical terminology and context, while the RAG system retrieves up-to-date clinical studies or patient data about the drug’s effects. Together, they produce responses that are both accurate in language and comprehensive in knowledge.
This hybrid strategy balances the strengths and weaknesses of each technique, offering an AI assistant capable of nuanced understanding and adaptive learning—perfect for industries with complex, evolving needs.
Practical Takeaways
Fine-Tuning is best when deep domain expertise and language understanding are critical, and training data is available.
RAG shines in scenarios needing up-to-the-minute information or when dealing with proprietary, external knowledge.
Combining them provides a robust solution that ensures both contextual precision and knowledge freshness.
Final Thoughts
Whether you prioritize specialization through fine-tuning or dynamic information retrieval with RAG, understanding their distinct roles helps you design more intelligent, responsive AI systems. And when combined, they open new horizons in creating AI that is both knowledgeable and adaptable—key for tackling complex real-world challenges.
0 notes
Text
Future Trend in Private Large Language Models
Future Trend in Private Large Language Models
As artificial intelligence rapidly evolves, private large language models (LLMs) are becoming the cornerstone of enterprise innovation. Unlike public models like GPT-4 or Claude, private LLMs are customized, secure, and fine-tuned to meet specific organizational goals—ushering in a new era of AI-powered business intelligence.
Why Private LLMs Are Gaining Traction
Enterprises today handle vast amounts of sensitive data. Public models, while powerful, may raise concerns around data privacy, compliance, and model control. This is where private large language models come into play.
A private LLM offers complete ownership, allowing organizations to train the model on proprietary data without risking leaks or compliance violations. Businesses in healthcare, finance, legal, and other highly regulated sectors are leading the shift, adopting tailored LLMs for internal knowledge management, chatbots, legal document analysis, and customer service.
If your enterprise is exploring this shift, here’s a detailed guide on building private LLMs customized for your business needs.
Emerging Trends in Private Large Language Models
1. Multi-Modal Integration
The next frontier is multi-modal LLMs—models that combine text, voice, images, and video understanding. Enterprises are increasingly deploying LLMs that interpret charts, understand documents with embedded visuals, or generate responses based on both written and visual data.
2. On-Premise LLM Deployment
With growing emphasis on data sovereignty, more organizations are moving toward on-premise deployments. Hosting private large language models in a secure, local environment ensures maximum control over infrastructure and data pipelines.
3. Domain-Specific Fine-Tuning
Rather than general-purpose capabilities, companies are now investing in domain-specific fine-tuning. For example, a legal firm might fine-tune its LLM for case law analysis, while a fintech company might tailor its model for fraud detection or compliance audits.
4. LLM + RAG Architectures
Retrieval-Augmented Generation (RAG) is becoming essential. Enterprises are combining LLMs with private databases to deliver up-to-date, verifiable, and domain-specific responses—greatly improving accuracy and reducing hallucinations.
Choosing the Right LLM Development Partner
Implementing a secure and scalable private LLM solution requires deep expertise in AI, data security, and domain-specific knowledge. Collaborating with a trusted LLM development company like Solulab ensures that your organization gets a tailored solution with seamless model deployment, integration, and ongoing support.
Solulab specializes in building enterprise-grade private LLMs that align with your goals—whether it’s boosting customer experience, automating workflows, or mining insights from unstructured data.
Final Thoughts
The future of enterprise AI lies in private large language models that are secure, customizable, and hyper-efficient. As businesses look to gain a competitive edge, investing in these models will no longer be optional—it will be essential.
With advancements in fine-tuning, multi-modal intelligence, and integration with real-time data sources, the next generation of LLMs will empower enterprises like never before.
To stay ahead in this AI-driven future, consider developing your own private LLM solution with a reliable LLM development company like Solulab today.
1 note
·
View note
Text
What Are the Key Technologies Behind Successful Generative AI Platform Development for Modern Enterprises?
The rise of generative AI has shifted the gears of enterprise innovation. From dynamic content creation and hyper-personalized marketing to real-time decision support and autonomous workflows, generative AI is no longer just a trend—it’s a transformative business enabler. But behind every successful generative AI platform lies a complex stack of powerful technologies working in unison.

So, what exactly powers these platforms? In this blog, we’ll break down the key technologies driving enterprise-grade generative AI platform development and how they collectively enable scalability, adaptability, and business impact.
1. Large Language Models (LLMs): The Cognitive Core
At the heart of generative AI platforms are Large Language Models (LLMs) like GPT, LLaMA, Claude, and Mistral. These models are trained on vast datasets and exhibit emergent abilities to reason, summarize, translate, and generate human-like text.
Why LLMs matter:
They form the foundational layer for text-based generation, reasoning, and conversation.
They enable multi-turn interactions, intent recognition, and contextual understanding.
Enterprise-grade platforms fine-tune LLMs on domain-specific corpora for better performance.
2. Vector Databases: The Memory Layer for Contextual Intelligence
Generative AI isn’t just about creating something new—it’s also about recalling relevant context. This is where vector databases like Pinecone, Weaviate, FAISS, and Qdrant come into play.
Key benefits:
Store and retrieve high-dimensional embeddings that represent knowledge in context.
Facilitate semantic search and RAG (Retrieval-Augmented Generation) pipelines.
Power real-time personalization, document Q&A, and multi-modal experiences.
3. Retrieval-Augmented Generation (RAG): Bridging Static Models with Live Knowledge
LLMs are powerful but static. RAG systems make them dynamic by injecting real-time, relevant data during inference. This technique combines document retrieval with generative output.
Why RAG is a game-changer:
Combines the precision of search engines with the fluency of LLMs.
Ensures outputs are grounded in verified, current knowledge—ideal for enterprise use cases.
Reduces hallucinations and enhances trust in AI responses.
4. Multi-Modal Learning and APIs: Going Beyond Text
Modern enterprises need more than text. Generative AI platforms now incorporate multi-modal capabilities—understanding and generating not just text, but also images, audio, code, and structured data.
Supporting technologies:
Vision models (e.g., CLIP, DALL·E, Gemini)
Speech-to-text and TTS (e.g., Whisper, ElevenLabs)
Code generation models (e.g., Code LLaMA, AlphaCode)
API orchestration for handling media, file parsing, and real-world tools
5. MLOps and Model Orchestration: Managing Models at Scale
Without proper orchestration, even the best AI model is just code. MLOps (Machine Learning Operations) ensures that generative models are scalable, maintainable, and production-ready.
Essential tools and practices:
ML pipeline automation (e.g., Kubeflow, MLflow)
Continuous training, evaluation, and model drift detection
CI/CD pipelines for prompt engineering and deployment
Role-based access and observability for compliance
6. Prompt Engineering and Prompt Orchestration Frameworks
Crafting the right prompts is essential to get accurate, reliable, and task-specific results from LLMs. Prompt engineering tools and libraries like LangChain, Semantic Kernel, and PromptLayer play a major role.
Why this matters:
Templates and chains allow consistency across agents and tasks.
Enable composability across use cases: summarization, extraction, Q&A, rewriting, etc.
Enhance reusability and traceability across user sessions.
7. Secure and Scalable Cloud Infrastructure
Enterprise-grade generative AI platforms require robust infrastructure that supports high computational loads, secure data handling, and elastic scalability.
Common tech stack includes:
GPU-accelerated cloud compute (e.g., AWS SageMaker, Azure OpenAI, Google Vertex AI)
Kubernetes-based deployment for scalability
IAM and VPC configurations for enterprise security
Serverless backend and function-as-a-service (FaaS) for lightweight interactions
8. Fine-Tuning and Custom Model Training
Out-of-the-box models can’t always deliver domain-specific value. Fine-tuning using transfer learning, LoRA (Low-Rank Adaptation), or PEFT (Parameter-Efficient Fine-Tuning) helps mold generic LLMs into business-ready agents.
Use cases:
Legal document summarization
Pharma-specific regulatory Q&A
Financial report analysis
Customer support personalization
9. Governance, Compliance, and Explainability Layer
As enterprises adopt generative AI, they face mounting pressure to ensure AI governance, compliance, and auditability. Explainable AI (XAI) technologies, model interpretability tools, and usage tracking systems are essential.
Technologies that help:
Responsible AI frameworks (e.g., Microsoft Responsible AI Dashboard)
Policy enforcement engines (e.g., Open Policy Agent)
Consent-aware data management (for HIPAA, GDPR, SOC 2, etc.)
AI usage dashboards and token consumption monitoring
10. Agent Frameworks for Task Automation
Generative AI platform Development are evolving beyond chat. Modern solutions include autonomous agents that can plan, execute, and adapt to tasks using APIs, memory, and tools.
Tools powering agents:
LangChain Agents
AutoGen by Microsoft
CrewAI, BabyAGI, OpenAgents
Planner-executor models and tool calling (OpenAI function calling, ReAct, etc.)
Conclusion
The future of generative AI for enterprises lies in modular, multi-layered platforms built with precision. It's no longer just about having a powerful model—it’s about integrating it with the right memory, orchestration, compliance, and multi-modal capabilities. These technologies don’t just enable cool demos—they drive real business transformation, turning AI into a strategic asset.
For modern enterprises, investing in these core technologies means unlocking a future where every department, process, and decision can be enhanced with intelligent automation.
0 notes
Text
AI Hallucinations: Causes, Detection, and Testing Strategies

What Are AI Hallucinations?
AI hallucinations occur when an artificial intelligence model generates incorrect, misleading, or entirely fabricated information with high confidence. These errors are particularly common in large language models (LLMs), image generators, and other generative AI systems.
Hallucinations can range from minor factual inaccuracies to completely nonsensical outputs, posing risks in applications like customer support, medical diagnosis, and legal research.
Types of AI Hallucinations
Factual Hallucinations — The AI presents false facts (e.g., incorrect historical dates).
Logical Hallucinations — The AI generates illogical or contradictory statements.
Contextual Hallucinations — The response deviates from the given context.
Creative Hallucinations — The AI invents fictional details (common in storytelling or image generation).
Causes of AI Hallucinations
Training Data Limitations — Gaps or biases in training data lead to incorrect inferences.
Over-Optimization — Models may prioritize fluency over accuracy.
Ambiguous Prompts — Poorly structured inputs can mislead the AI.
Lack of Ground Truth — Without real-world validation, models may “guess” incorrectly.
Impact of AI Hallucinations
Loss of Trust — Users may stop relying on AI-generated content.
Operational Risks — Errors in healthcare, finance, or legal advice can have serious consequences.
Reputation Damage — Businesses deploying unreliable AI may face backlash.
How to Detect AI Hallucinations
Fact-Checking — Cross-reference outputs with trusted sources.
Consistency Testing — Ask the same question multiple times to check for contradictions.
Human Review — Subject matter experts verify AI responses.
Adversarial Testing — Use edge-case prompts to expose weaknesses.
Testing Methodologies for AI Hallucinations
1. Automated Validation
Rule-Based Checks — Define constraints (e.g., “Never suggest harmful actions”).
Semantic Similarity Tests — Compare AI responses against verified answers.
Retrieval-Augmented Validation — Use external databases to verify facts.
2. Human-in-the-Loop Testing
Expert Review Panels — Domain specialists evaluate AI outputs.
Crowdsourced Testing — Leverage diverse user feedback.
3. Stress Testing
Input Perturbation — Slightly alter prompts to test robustness.
Out-of-Distribution Testing — Use unfamiliar queries to assess generalization.
Metrics for Evaluating AI Hallucinations

Mitigating AI Hallucinations in Model Design
Fine-Tuning with High-Quality Data — Reduce noise in training datasets.
Reinforcement Learning from Human Feedback (RLHF) — Align models with human preferences.
Retrieval-Augmented Generation (RAG) — Integrate external knowledge sources.
Uncertainty Calibration — Make AI express confidence levels in responses.
Best Practices for QA Teams
✔ Implement Continuous Monitoring — Track hallucinations in production. ✔ Use Diverse Test Cases — Cover edge cases and adversarial inputs. ✔ Combine Automated & Manual Testing — Balance speed with accuracy. ✔ Benchmark Against Baselines — Compare performance across model versions.
Using Genqe.ai for Hallucination Testing
Automated fact-checking pipelines
Bias and hallucination detection APIs
Real-time monitoring dashboards
The Future of Hallucination Testing
Self-Correcting AI Models — Systems that detect and fix their own errors.
Explainability Enhancements — AI that provides sources for generated content.
Regulatory Standards — Governments may enforce hallucination testing in critical AI applications.
Conclusion
AI hallucinations are a major challenge in deploying reliable generative AI. By combining automated testing, human oversight, and advanced mitigation techniques, organizations can reduce risks and improve model trustworthiness. As AI evolves, hallucination detection will remain a key focus for QA teams and developers.
Would you like a deeper dive into any specific testing technique?
0 notes
Text
What causes hallucination in LLM-generated factual responses?
Hallucination in large language models (LLMs) refers to the generation of content that appears syntactically and semantically correct but is factually inaccurate, misleading, or entirely fabricated. This issue arises from the inherent design of LLMs, which are trained on massive corpora of text data using next-token prediction rather than explicit factual verification.
LLMs learn statistical patterns in language rather than structured knowledge, so they do not have a built-in understanding of truth or falsehood. When asked a question, the model generates responses based on learned probabilities rather than real-time fact-checking or grounding in an authoritative source. If the training data contains inaccuracies or lacks sufficient information about a topic, the model may "hallucinate" a plausible-sounding answer that is incorrect.
Another contributing factor is prompt ambiguity. If a prompt is unclear or open-ended, the model may attempt to fill in gaps with invented details to complete a coherent response. This is especially common in creative tasks, speculative prompts, or when answering with limited context.
Additionally, hallucination risk increases in zero-shot or few-shot settings where models are asked to perform tasks without specific fine-tuning. Reinforcement Learning from Human Feedback (RLHF) helps mitigate hallucination to an extent by optimizing outputs toward human preferences, but it does not eliminate the issue entirely.
Efforts to reduce hallucinations include grounding LLMs with retrieval-augmented generation (RAG), fine-tuning on high-quality curated datasets, and incorporating external knowledge bases. These strategies anchor responses to verifiable facts, making outputs more reliable.
Understanding and mitigating hallucinations is essential for safely deploying LLMs in domains like healthcare, finance, and education, where factual accuracy is critical. Techniques to identify, minimize, and prevent hallucinations are covered in-depth in the Applied Generative AI Course.
0 notes
Text
Designed IBM LoRA Adapter Inference Improves LLM Ability

LLMs express themselves faster to new adaptors.
IBM LoRA
IBM Research has modified the low-rank adapter, IBM LoRA, to give Large Language Models (LLM) specialised features at inference time without delay. Hugging Face now has task-specific, inference-friendly adapters.
Low-rank adapters (LoRAs) may swiftly empower generalist big language models with targeted knowledge and skills for tasks like summarising IT manuals or assessing their own replies. However, LoRA-enhanced LLMs might quickly lose functionality.
Switching from a generic foundation model to one customised via LoRA requires the customised model to reprocess the conversation up to that point, which might incur runtime delays owing to compute and memory costs.
IBM Research created a wait-shortening approach. A “activated” IBM LoRA, or “a” LoRA, allows generative AI models to reuse computation they have already done and stored in memory to deliver results faster during inference time. With the increased usage of LLM agents, quick job switching is crucial.
Like IBM LoRA, aLoRAs may perform specialist jobs. However, aLoRAs can focus on base model-calculated embeddings at inference time. As their name indicates, aLoRAs may be "activated" independently from the underlying model at any time and without additional costs since they can reuse embeddings in key value (KV) cache memory.
According to the IBM researcher leading the aLoRA project, “LoRA must go all the way back to the beginning of a lengthy conversation and recalculate it, while aLoRA does not.”
IBM researchers say an engaged LoRA can accomplish tasks 20–30 times faster than a normal LoRA. Depending on the amount of aLoRAs, an end-to-end communication might be five times faster.
ALoRA: Runtime AI “function” for faster inference
IBM's efforts to expedite AI inferencing led to the idea of a LoRA that might be activated without the base model. LoRA adapters are a popular alternative to fine-tuning since they may surgically add new capabilities to a foundation model without updating its weights. With an adapter, 99 percent of the customised model's weights stay frozen.
LoRAs may impede inferencing despite their lower customisation costs. It takes a lot of computation to apply their adjusted weights to the user's queries and the model's replies.
IBM researchers aimed to reduce work by employing changed weights alone for generation. By dynamically loading an external software library containing pre-compiled code and running the relevant function, statically linked computer programs can execute tasks they weren't planned for.
As their name indicates, aLoRAs may be "activated" independently from the underlying model at any time and without additional costs since they can reuse embeddings in key value (KV) cache memory. An LLM configured with standard LoRAs (left) must reprocess communication for each new IBM LoRA. In contrast, different aLoras (right) can reuse embeddings generated by the basic model, saving memory and processing.
Researchers must execute an AI adaptor without task-aware embeddings that explain the user's request to make it act like a function. Without user-specific embeddings, their activated-LoRA prototypes were inaccurate.
However, they fixed that by raising the adapter's rating. The adapter can now extract more contextual indications from generic embeddings to increased network capacity. After a series of testing, researchers found that their “aLoRA” worked like a LoRA.
Researchers found that aLoRA-customized models could create text as well as regular LoRA models in many situations. One might increase runtime without losing precision.
Artificial intelligence test adapter “library”
IBM Research is offering a library of Granite 3.2 LLM aLoRA adapters to improve RAG application accuracy and reliability. Experimental code to execute the adapters is available as researchers integrate them into vLLM, an open-source platform for AI model delivery. IBM distributes regular Granite 3.2 adapters separately for vLLM usage. Some IBM LoRA task-specific enhancements were provided through Granite Experiments last year.
One of the new aLoRAs may reword discussion questions to help discover and retrieve relevant parts. To reduce the chance that the model may hallucinate an answer, another might evaluate if the retrieved documents can answer a question. A third might indicate the model's confidence in its result, urging users to verify their information.
In addition to Retrieval Augmented Generation (RAG), IBM Research is creating exploratory adapters to identify jailbreak attempts and decide whether LLM results meet user-specified standards.
Agent and beyond test time scaling
It has been shown that boosting runtime computing to analyse and improve model initial responses enhances LLM performance. IBM Research improved Granite 3.2 models' reasoning by providing different techniques to internally screen LLM replies during testing and output the best one.
IBM Research is investigating if aLoRAs can enhance “test-time” or “inference-time” scalability. An adapter may be created to generate numerous answers to a query and pick the one with the highest accuracy confidence and lowest hallucination risk.
Researchers want to know if inference-friendly adapters affect agents, the next AI frontier. When a difficult job is broken down into discrete stages that the LLM agent can execute one at a time, AI agents can mimic human thinking.
Specialised models may be needed to implement and assess each process.
#technology#technews#govindhtech#news#technologynews#IBM LoRA#LoRA#ALoRA#artificial intelligence#low-rank adapters#LoRAs
0 notes
Text
A Technical and Business Perspective for Choosing the Right LLM for Enterprise Applications.
In 2025, Large Language Models (LLMs) have emerged as pivotal assets for enterprise digital transformation, powering over 65% of AI-driven initiatives. From automating customer support to enhancing content generation and decision-making processes, LLMs have become indispensable. Yet, despite the widespread adoption, approximately 46% of AI proofs-of-concept were abandoned and 42% of enterprise AI projects were discontinued, mainly due to challenges around cost, data privacy, and security. A recurring pattern identified is the lack of due diligence in selecting the right LLM tailored to specific enterprise needs. Many organizations adopt popular models without evaluating critical factors such as model architecture, operational feasibility, data protection, and long-term costs. Enterprises that invested time in technically aligning LLMs with their business workflows, however, have reported significant outcomes — including a 40% drop in operational costs and up to a 35% boost in process efficiency.
LLMs are rooted in the Transformer architecture, which revolutionized NLP through self-attention mechanisms and parallel processing capabilities. Components such as Multi-Head Self-Attention (MHSA), Feedforward Neural Networks (FFNs), and advanced positional encoding methods (like RoPE and Alibi) are essential to how LLMs understand and generate language. In 2025, newer innovations such as FlashAttention-2 and Sparse Attention have improved speed and memory efficiency, while the adoption of Mixture of Experts (MoE) and Conditional Computation has optimized performance for complex tasks. Tokenization techniques like BPE, Unigram LM, and DeepSeek Adaptive Tokenization help break down language into machine-understandable tokens. Training strategies have also evolved. While unsupervised pretraining using Causal Language Modeling and Masked Language Modeling remains fundamental, newer approaches like Progressive Layer Training and Synthetic Data Augmentation are gaining momentum. Fine-tuning has become more cost-efficient with Parameter-Efficient Fine-Tuning (PEFT) methods such as LoRA, QLoRA, and Prefix-Tuning. Additionally, Reinforcement Learning with Human Feedback (RLHF) is now complemented by Direct Preference Optimization (DPO) and Contrastive RLHF to better align model behavior with human intent.
From a deployment perspective, efficient inference is crucial. Enterprises are adopting quantization techniques like GPTQ and SmoothQuant, as well as memory-saving architectures like xFormers, to manage computational loads at scale. Sparse computation and Gated Experts further enhance processing by activating only the most relevant neural pathways. Retrieval-Augmented Generation (RAG) has enabled LLMs to respond in real-time with context-aware insights by integrating external knowledge sources. Meanwhile, the industry focus on data security and privacy has intensified. Technologies like Federated Learning, Differential Privacy, and Secure Multi-Party Computation (SMPC) are becoming essential for protecting sensitive information. Enterprises are increasingly weighing the pros and cons of cloud-based vs. on-prem LLMs. While cloud LLMs like GPT-5 and Gemini Ultra 2 offer scalability and multimodal capabilities, they pose higher privacy risks. On-prem models like Llama 3, Falcon 2, and DeepSeek ensure greater data sovereignty, making them ideal for sensitive and regulated sectors.
Comparative evaluations show that different LLMs shine in different use cases. GPT-5 excels in customer service and complex document processing, while Claude 3 offers superior ethics and privacy alignment. DeepSeek and Llama 3 are well-suited for multilingual tasks and on-premise deployment, respectively. Models like Custom ai Gemini Ultra 2 and DeepSeek-Vision demonstrate impressive multimodal capabilities, making them suitable for industries needing text, image, and video processing. With careful evaluation of technical and operational parameters — such as accuracy, inference cost, deployment strategy, scalability, and compliance — enterprises can strategically choose the right LLM that fits their business needs. A one-size-fits-all approach does not work in LLM adoption. Organizations must align model capabilities with their core objectives and regulatory requirements to fully unlock the transformative power of LLMs in 2025 and beyond.
0 notes
Text
{RAG vs.Fine-Tuning}: Which Approach Delivers Better Results for LLMs?
Imagine you’re building your dream home. You could either renovate an old house, making changes to the layout, adding new features, and fixing up what’s already there (Fine-Tuning), or you could start from scratch, using brand-new materials and designs to create something totally unique (RAG). In AI, Fine-Tuning means improving an existing model to work better for your specific needs, while Retrieval-Augmented Generation (RAG) adds external information to make the model smarter and more flexible. Just like with a home, which option {RAG vs.Fine-Tuning} you choose depends on what you want to achieve. Today, we’ll check out both the approaches to help you decide which one is right for your goals.
What Is LLM?
Large Language Models (LLMs) have taken the AI world by storm, capable of generating different types of content, answering queries, and even translating languages. As they are trained on extensive datasets, LLM showcase incredible versatility but they often struggle with outdated or context-specific information, limiting their effectiveness.
Key Challenges with LLMs:
LLMs can sometimes provide incorrect answers, even when sounding confident.
They may give responses that are off-target or irrelevant to the user's question.
LLMs rely on fixed datasets, leading to outdated or vague information that misses user specifics.
They can pull information from unreliable sources, risking the spread of misinformation.
Without understanding the context of a user’s question, LLMs might generate generic responses that are not helpful.
Different fields may use the same terms in various ways, causing misunderstandings in responses.
LLUMO AI's Eval LM makes it easy to test and compare different Large Language Models (LLMs). You can quickly view hundreds of outputs side by side to see which model performs best, and deliver accurate answers quickly, without losing quality.
How RAG Works?
Retrieval-augmented generation (RAG) is used to merge the strengths of generative models with retrieval-based systems. It retrieves relevant documents or data from an external database,websites or from any reliable source to enhance its responses and produce outputs not only accurate but also contextually latest and relevant.
A customer support chatbot that uses RAG, suppose a user asks about a specific product feature or service, the chatbot can quickly look up related FAQs, product manuals, and recent user reviews in its database. Combining this information creates a response that is latest, relevant, and helpful.
How RAG tackle LLM Challenges?
Retrieval-Augmented Generation (RAG) steps in to enhance LLMs and tackle these challenges:
Smart Retrieval: RAG first looks for the most relevant and up-to-date information from reliable sources, ensuring that responses are accurate.
Relevant Context: By giving the LLM specific, contextual data, RAG helps generate answers that are not only correct but also tailored to the user’s question.
Accuracy: With access to trustworthy sources, RAG greatly reduces the chances of giving false or misleading information, improving user trust.
Clarified Terminology: RAG uses diverse sources to help the LLM understand different meanings of terms, and minimizes the chances of confusion.
RAG turns LLMs into powerful tools that deliver precise, latest, and context-aware answers. This leads to better accuracy and consistency in LLM outputs. Think of it as a magic wand for today’s world, providing quick, relevant, and accurate answers right when you need them most.
How Fine-tuning Works?
Fine-tuning is a process where a pre-trained language model is adapted to a dataset relevant to a particular domain. It is particularly effective when you have a large amount of domain-specific data, allowing the model to perform exceptionally on that particular task. This process not only reduces computational costs but also allows users to tackle advanced models without starting from scratch.
A medical diagnosis tool designed for healthcare professionals. By fine-tuning a LLM on a dataset of patient records and medical literature, the model can learn that particular medical terminology and generate insights based on specific symptoms. For example, when a physician inputs symptoms, the fine-tuned model can offer potential diagnoses and treatment options tailored to that specific context.
How Fine-Tuning Makes a Difference in LLM
Fine-tuning is a powerful way to enhance LLMs and tackle these challenges effectively:
Tailored Training: Fine-tuning allows LLMs to be trained on specific datasets that reflect the specific information they’ll need to provide. This means they can learn the most relevant knowledge of the particular.
Improved Accuracy: By focusing on the right data, fine-tuning helps LLMs to deliver more precise answers that directly address user questions, and reduces the chances of misinformation.
Context Awareness: Fine-tuning helps LLMs to understand the context better, so they can generate most relevant and appropriate responses.
Clarified Terminology: With targeted training, LLMs can learn the nuances of different terms and phrases, helping them avoid confusion and provide clearer answers.
Fine-tuning works like a spell, transforming LLMs into powerful allies that provide answers that are not just accurate, but also deeply relevant and finely attuned to context. This enchanting enhancement elevates the user experience to new heights, creating a seamless interaction that feels almost magical.
How can LLumo AI help you?
In {RAG vs.Fine-Tuning}, LLUMO can help you gain complete insights on your LLM outputs and customer success using proprietary framework- Eval LM. To use LLumo Eval LM and evaluate your prompt output to generate insights needs follow these steps:
Step 1: Create a New Playground
Go to the Eval LM platform.
Click on the option to create a new playground. This is your workspace for generating and evaluating experiments.

Step 2: Choose How to Upload Your Data
In your new playground, you have three options for uploading your data:
Upload Your Data:
Simply drag and drop your file into the designated area. This is the quickest way to get your data in.

Choose a Template:
Select a template that fits your project. Once you've chosen one, upload your data file to use it with that template.

Customize Your Template:
If you want to tailor the template to your needs, you can add or remove columns. After customizing, upload your data file.

Step 3: Generate Responses
After uploading your data, click the button to run the process. This will generate responses based on your input.
Step 4: Evaluate Your Responses
Once the responses are generated, you can evaluate them using over 50 customizable Key Performance Indicators (KPIs).
You can define what each KPI means to you, ensuring it fits your evaluation criteria.

Step 5: Set Your Metrics
Choose the evaluation metrics you want to use. You can also select the language model (LLM) for generating responses.
After setting everything, you'll receive an evaluation score that indicates whether the responses pass or fail based on your criteria.
Step 6: Finalize and Run
Once you’ve completed all the setup, simply click on “Run.”
Your tailored responses are now ready for your specific niche!
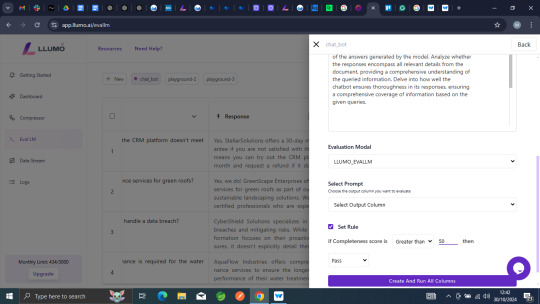
Step 6: Evaluate you Accuracy Score
After generating responses, you can easily check how accurate they are. You can set your own rules to decide what counts as a good response, giving you full control over accuracy.

Why Choose Retrieval-Augmented Generation (RAG) in {RAG vs.Fine-Tuning}?
On a frequent basis, AI developers used to face challenges like data privacy, managing costs, and delivering accurate outputs. RAG effectively addresses these by offering a secure environment for data handling, reducing resource requirements, and enhancing the reliability of results. By choosing RAG over fine-tuning in {RAG vs.Fine-Tuning},companies can not only improve their operational efficiency but also build trust with their users through secure and accurate AI solutions.
While choosing {RAG vs.Fine-Tuning}, Retrieval-Augmented Generation (RAG) often outshines fine-tuning. This is primarily due to its security, scalability, reliability, and efficiency. Let's explore each of these with real-world use cases.
Data Security and Data Privacy
One of the biggest concerns for AI developers is data security. With fine-tuning, the proprietary data used to train the model becomes part of the model’s training set. This means there’s a risk of that data being exposed, potentially leading to security breaches or unauthorized access. In contrast, RAG keeps your data within a secured database environment.
Imagine a healthcare company using AI to analyze patient records. By using RAG, the company can pull relevant information securely without exposing sensitive patient data. This means they can generate insights or recommendations while ensuring patient confidentiality, thus complying with regulations like HIPAA.
Cost-Efficient and Scalable
Fine-tuning a large AI model takes a lot of time and resources because it needs labeled data and a lot of work to set up. RAG, however, can use the data you already have to give answers without needing a long training process. For example, an e-commerce company that wants to personalize customer experiences doesn’t have to spend weeks fine-tuning a model with customer data. Instead, they can use RAG to pull information from their existing product and customer data. This helps them provide personalized recommendations faster and at a lower cost, making things more efficient.
Reliable Response
The effectiveness of AI is judged by its ability to provide accurate and reliable responses. RAG excels in this aspect by consistently referencing the latest curated datasets to generate outputs. If an error occurs, it’s easier for the data team to trace the source of the response back to the original data, helping them understand what went wrong.
Take a financial advisory firm that uses AI to provide investment recommendations. By employing RAG, the firm can pull real-time market data and financial news to inform its advice. If a recommendation turns out to be inaccurate, the team can quickly identify whether the error stemmed from outdated information or a misinterpretation of the data, allowing for swift corrective action.
Let’s Check Out the Key Points to Evaluate {RAG vs.Fine-Tuning}
Here’s a simple tabular comparison between Retrieval-Augmented Generation (RAG) and Fine-Tuning:
Feature
Retrieval-Augmented Generation (RAG)
Fine-Tuning
Data Security
Keeps proprietary data within a secured database.
Data becomes part of the model, risking exposure.
Cost Efficiency
Lower costs by leveraging existing data; no training required.
Resource-intensive, requiring time and compute power.
Scalability
Easily scalable as it uses first-party data dynamically.
Scaling requires additional training and resources.
Speed of Implementation
Faster to implement; no lengthy training process.
Slower due to the need for extensive data preparation.
Accuracy of Responses
Pulls from the latest data for accurate outputs.
Performance may vary based on training data quality.
Error Tracking
Easier to trace errors back to specific data sources.
Harder to identify where things went wrong.
Use Case Flexibility
Adapts quickly to different tasks without retraining.
Best for specific tasks but less adaptable.
Development Effort
Requires less human effort and time.
High human effort needed for labeling and training.
Summing Up
Choosing between {RAG vs.Fine-Tuning},ultimately depends on your specific needs and resources. RAG is time and again the better option because it keeps your data safe, is more cost-effective, and can quickly adapt the latest information. This means it can provide accurate and relevant answers based on the latest data, which keeps you update.
On the other hand, Fine-Tuning is great for specific tasks but can be resource-heavy and less flexible. It shines in niche areas, but it doesn't handle changes as well as RAG does. Overall, RAG usually offers more capabilities for a wider range of needs. With LLUMO AI’s Eval LM, you can easily evaluate and compare model performance, helping you optimize both approaches. LLUMO’s tools ensure your AI delivers accurate, relevant results while saving time and resources, regardless of the method you choose
0 notes